
Since the 1940s, the military departments, including the Department of the Navy (DON), have created myriad information and operations systems to support mission-critical workflows, including readiness tracking, reporting for peers and higher-level authorities, formal audit and financial integrity initiatives, and real-time command and control. Each effort was independently launched to satisfy varying requirements for different use cases and customers. As an unintended consequence, DON has collected more data than it can digest and use. In addition, data has become scattered across disconnected systems, making the whole ecosystem less effective than the sum of its parts.
As data silos have accumulated and multiplied, this disconnected architecture has inhibited timely, data-driven decision-making. What is the best architecture the department can deploy to bring these systems together to provide operators analytics at the edge?
Traditionally, DON has used data lakes—large, centralized repositories of raw data in native formats drawn from a variety of systems, applications, and equipment—to manage data silos. But defense personnel and observers alike have argued that current data lake efforts, some of which the department continues to pursue, are not providing timely, current, or relevant data and are falling short of requirements. One recent Proceedings article proposes an alternate framework—“data brokering”—as the solution to these challenges.1 That article describes data brokering as a system enabled by a web of application programming interfaces (APIs) that provides machine-to-machine connections between otherwise disconnected information and operations systems.
While data brokering could offer new benefits, it also would introduce critical risks into the enterprise data structure and require significant, costly reengineering of legacy information systems. Instead, DON should pursue a middle road strategy: “data as a service,” in which data is still centralized within a common repository, but the connections between systems are automated and machine-to-machine driven.
Data Lake: The Traditional Approach
Though data lakes have been used to store data for decades, public and private enterprises began adopting them widely in the 2010s. Data lakes rely on human users to manually bring data from a variety of siloed sources into a single centralized repository. This transfer is time and cost intensive, and the resulting repository maintains the data in the formatting carried over from each siloed source. Thus, to make the data contained in the lake useful, analysts and operators must first manually transform the subsets that are of interest to make them interoperable with each other before applying them to workflows.
The data lake concept offers some advantages—namely, security and simplicity.2 First, because each data source shares information only with the lake, the architecture’s defensible surface area is smaller and more centralized than that of more complex data architectures, providing more resilience against cyberattacks. Second, while human operators must invest significant effort to create, maintain, and update the data lake, merged data remains accessible once parked in the lake. Finally, by storing all information in a central repository, an enterprise can rely on its data lake to formulate and implement policy around which data sources are authoritative on which topics. This enables policies to evolve over time without rearchitecting numerous system connections.
However, for data lakes, simplicity is as much a curse as a blessing. The largest challenges are the time, money, and manpower required to continually update the repository. Refreshing the data as it changes requires a high level of effort for a low-quality result; because data is not updated live, manual refresh efforts delay analysis, and users lack confidence that the data they are working with is current.
In addition, data lakes limit the utility of tools and applications connected to the data ecosystem. Information cannot be easily exported to newly connected applications, locking in legacy features and slowing the integration of new technology. To use an analogy, it takes significant manual effort to get a “warm shower” out of a “cold” data lake, unless the enterprise is willing to invest significantly in the architecture and tooling required to complete that work automatically.
Compounding these shortcomings, existing data lake architectures flow unidirectionally and usually asynchronously (see Figure 1). This can be acceptable if the enterprise aspires to leverage data for only asynchronous or time-delayed analytical and reporting workflows, but it can be debilitating if data is required to support real-time, operational, or edge decision-making. Data lakes are unable to capture and record decisions and their underlying data; nor are they able to quickly distribute this information back to the rest of the enterprise. As a result, many observers have argued that data lakes are more like “data swamps,” in which dynamic information flows in, only to slowly stagnate over time.3 Unfortunately, DON has prioritized data lakes as its main approach to the data problem, often to the detriment of concurrent operations.
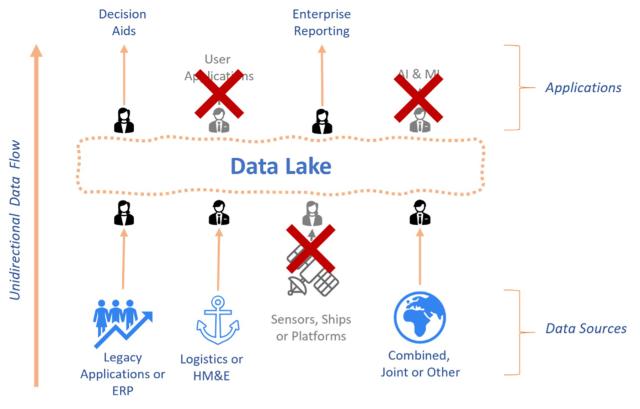
Credit: All figures courtesy of the authors
Data Brokering: A Complex Alternative
DON could implement a data brokering solution to overcome the deficiencies of the data lake. By creating an extensive network of machine-to-machine API connections, or direct links among data sources and the various programs and interfaces users wish to integrate with the data, a data brokering solution would allow the department to push data across the enterprise in real time. While this could offer improvements over the current approach—primarily through increased automation—it also would carry risks and challenges.
When leveraged for data architecture, a data brokering approach carries a few notable disadvantages, including high upfront development costs to rearchitect legacy systems to provide modern APIs and increased exposure to cyber vulnerabilities at each point-to-point connection between systems. The department would have to establish an exponential number of new API connections for each additional service it integrates into its data ecosystem.
Another disadvantage is that most APIs are rate-limited and are not capable of moving large quantities of data—such as sensor data—at scale. Finally, the web of connections between systems makes it difficult for the department to establish or define which sources are “authoritative” and trusted in any given context.
Because of the complexity of this framework, modernizing or replacing any legacy data source would require a substantial effort to update the capabilities that are connected to the source in the data ecosystem (see Figure 2). As systems multiply, the cost of removing or replacing a single outdated component or capability swells from merely high to unaffordable, rendering organizational changes difficult, if not impossible. As a long-term result of this web of interconnection, DON could eventually ensnare itself in a net of aging capabilities it is unable to rationalize or maintain.

The API approach also increases critical Department of Defense (DoD) systems’ vulnerabilities by exponentially increasing the protectable surface area with each new connection.4 While data lake architects must protect connections between each data source and application and the data lake, data brokering architects must protect connections from every data source to every application, creating a resilience nightmare. Security is further diminished within the data brokering approach because the framework disaggregates responsibility for user authentication and access control across the distributed API architecture rather than managing it centrally and consistently. Proponents of data brokering suggest access control could be built on top of the Global Force Management Data Initiative (GFMDI), DoD’s current solution for tracking and depicting force structure. However, GFMDI data is not comprehensively updated, meaning it is neither reliable nor accurate enough to be depended on to gate access to the department’s sensitive data with sufficient reliability.
Data as a Service: The Best of Both Worlds
A solution to DON’s complex data management problem lies not in incurring significant cost to create a web of API connections for data brokerage, but in building on existing investments by creating a single data layer API, to provide enterprise data to downstream consumers as a service (see Figure 3). The data-as-a-service architecture takes the best elements of both the data lake and data brokering solutions to provide a structure that makes the addition or replacement of components within a network far simpler than would be possible in an interconnected web of APIs. With fewer connections, the data layer also presents a reduced surface area requiring cyber defense. In addition, all access controls can be managed centrally within the data layer and propagated across applications with consistency. This creates a more secure, trustworthy network.

The key innovation that enables this kind of hybrid architecture is software that can be installed on existing legacy systems. Such software is capable of reading from and writing to the existing legacy system and then communicating directly with the integrated data layer above. This achieves the effect of the automated machine-to-machine connection (which data lakes lack) without the complexity or expensive reengineering associated with the pure API approach. The technology exists today and is already used across the public and private sectors.
Data as a service also presents unique opportunities to power next-generation data integration, analysis, and operations. For example, the data layer provides bidirectional connectivity, which allows each connected component to read from and write back to the centralized data repository in real time. Unlike the unidirectional data lake, which keeps data locked in disparate siloes and ignored until a manual integration makes it discoverable organization wide, the bidirectional data layer ensures new information continuously flows throughout the organization to support operational decision-making.
In addition, the data layer can provide DoD and DON operational resilience in denied, disrupted, intermittent, and limited bandwidth environments by enabling forward-deployed platforms to clone relevant subsets of the data layer and maintain that data locally, regardless of network connectivity. In low-bandwidth environments, users can prioritize information types to synchronize as bandwidth is available. Once connectivity is restored, all new information can sync back to the master data layer to reconcile changes made on both sides.
Finally, the data-as-a-service approach can improve data quality through bidirectional feedback across systems. These improvements will be backed by more accurate, granular security controls to reduce risk compared to both data brokering and data lake solutions. Best of all, a data layer could offer an expeditious route for DoD to solve its critical data management problem: Data layer solutions are commercially available and have a proven record of securely supporting integration, analysis, and operations across defense, government, and commercial applications.
The Departments of the Navy and Defense have rightly focused on the importance of data, data architectures, and data management in their quest to capitalize on commercial-driven advances in information technology, artificial intelligence, and machine-learning. Embracing data as a service will bring security, scalability, flexibility, and life-cycle savings to the acquisition and fielding of capabilities essential to both real-time operational functions and offline management and logistics tasks. Given its potential to revolutionize data operations, the data layer approach merits further exploration by DON.
1. Maj Julia Weber, USMC, “The Pentagon Needs to Adopt Data-Brokering Solutions,” U.S. Naval Institute Proceedings 148, no.4 (April 2022).
2. Amazon AWS, “What Is a Data Lake?”
3. Christian Lauer, “What Is a Data Swamp?” Medium.com, 28 December 2021.
4. Open Web Application Security Project (OWASP) Foundation, “OWASP Security Project.”


